
TFGI: Leslie, it’s a pleasure to have you here. Could you share a bit about your background and the role you play at AI Singapore?
In my background, economics and finance paved the way for years of work in macro-economic policy-making and investment strategy. Recognising the transformative potential of big data, fast networks, and powerful computing a decade ago, I pivoted towards data science and AI. About a year and a half ago, I took on the role of leading the product work at AI Singapore, a national program funded by Singapore’s National Research Foundation to enhance the country’s AI capabilities.
TFGI: For those less familiar with AI terminology, could you simplify what Large Language Models (LLMs) are and explain their role in the broader spectrum of Generative AI?
Generative AI creates new content rather than just analysing data. Large Language Models (LLMs), such as ChatGPT, focus on generating text and serve as versatile Foundation Models that require tuning for specific applications. They can create diverse content like text, images, and music.
LLMs are designed to understand and generate human language, trained on vast amounts of text data. However, existing models often display bias due to training data sourced predominantly from Western societies.
TFGI: Moving on to your recent initiatives, what prompted the focus on developing multimodal and localised LLMs specifically tailored for Singapore and Southeast Asia?
Recognising the potential economic and social impact of LLMs, we turned our attention to the scarcity of Southeast Asian data in existing models. Most LLMs are trained on Western data, leading to biases and performance gaps for Southeast Asian languages. Our goal is to bridge this gap by developing open-source LLMs like SEA-LION, focusing on representing the region’s 600 million citizens and their diverse cultures.
TFGI: Southeast Asian Languages in One Network (SEA-LION), AI Singapore’s Southeast Asian Languages in One Network, is designed as a family of open-source LLMs for SEA use cases. Can you delve into the significance of this model and how it contributes to representing the cultural contexts of Southeast Asia?
SEA-LION, trained on 11 languages used in Southeast Asia, stands out with its emphasis on regional tasks. It addresses language nuances that many other models overlook, contributing to a better understanding of Southeast Asian languages and cultures. By open-sourcing data and measures, we aim to encourage collaborative efforts to enhance LLMs in the region.
At the heart of understanding the SEA region lies the issue of language tokenisation. Existing tokenisers of popular LLMs are often English-centric. We created a custom SEABPETokeniser for optimal model performance after testing various approaches. Our SEABPETokeniser is designed to balance fertility and proportion of continued words, considering linguistic nuances.
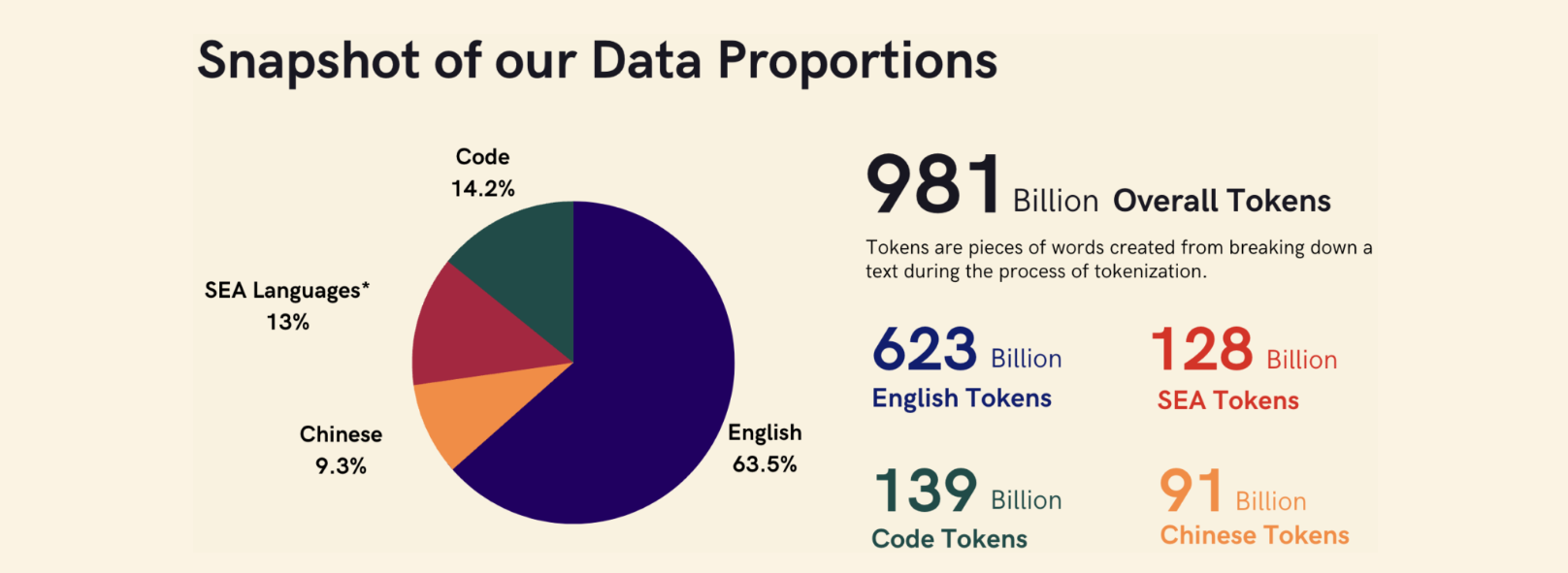
TFGI: As part of the National Multimodal Large Language Model (LLM) Programme, how does SEA-LION contribute to advancing Singapore’s research and engineering capabilities, especially in the realm of multi-modal Large Language Models?
Given the rapidly evolving technology, there’s a strategic need to develop sovereign capabilities in LLMs, considering the unique cultural contexts of Singapore and the Southeast Asian region. This initiative emphasises the development of multimodal and localised LLMs for understanding the diverse cultures and languages of Southeast Asia. SEA-LION plays a crucial role in building expertise among our AI engineers and scientists, contributing to local and regional LLMs. As part of A*Star‘s efforts, SEA-LION, will expand to include audio capabilities, further advancing Singapore’s capabilities in multi-modal LLMs.
TFGI: Looking ahead, what developments and outcomes can we anticipate from the National Multimodal Large Language Model (NMLP) over the next two years?
Over the next two years, our goal is to expand data sets for text and speech, releasing sets with three trillion tokens. We plan to build better-performing models, incorporating speech and exploring approaches like a mixture of experts. Through partnerships with commercial, public, and NGO sectors, we aim to validate the utility of these models and foster a vibrant open-source community. The ongoing effort in research, engineering, governance, computing, and enterprise AI use cases will develop models and use cases. Building on early outcomes of AI Singapore‘s SEA-LION1 model, which is more representative of Southeast Asia’s cultural contexts and linguistic nuances, SEA-LION will evolve and extend into a multimodal speech-text model, offering a cost-effective and efficient option for enterprises in Southeast Asia to incorporate AI into their workflows.
About the organisation
Launched in May 2017, AI Singapore brings together all Singapore-based research institutions and the vibrant ecosystem of AI start-ups and companies developing AI products to perform use-inspired research, grow knowledge, create tools, and develop the talent to power Singapore’s AI efforts.



